









Bevezetés
Az Érintő előző számában Maga Balázs és Simon Péter gépi látásról szóló cikke révén betekintést nyerhettünk abba, hogyan tudnak a mesterséges neurális hálók röntgen- vagy CT-felvételeket értelmezni, illetve miképpen tanulnak meg képeket osztályozni. Ezúttal a neurális hálók egy másik rendkívül izgalmas alkalmazási területét mutatjuk be: azt, hogy miként képesek szövegek megértésére és előállítására – egyszóval hogyan jönnek létre a nagy nyelvi modellek (angol rövidítéssel: LLM-ek, azaz Large Language Model-ek). Olyan fejlesztések „motorjáról” lesz szó, amelyeket ma már gombnyomásra használhatunk a különböző chatbotokban, automatikus fordítókban vagy épp programozási segédeszközökben.
Az alábbiakban, a gépi látásról szóló cikk stílusához hasonlóan, igyekszünk intuitív képet adni arról, hogy mit is takar egy nagy nyelvi modell, hogyan tud önállóan szövegeket létrehozni, miért fordulhat elő, hogy téved vagy épp túl magabiztos lesz, és milyen kihívásokkal szembesülünk a fejlesztése során.
Mi is egy nagy nyelvi modell?
Röviden megfogalmazva, egy nagy nyelvi modell olyan mesterséges neurális háló, amelyet úgy tanítottak be, hogy képes legyen emberi nyelven írt szövegeket elemezni és generálni. A „nagy” jelző arra utal, hogy ezek a modellek rengeteg paramétert tartalmaznak – a mai legfejlettebb modellek akár több százmilliárd beállítható értékkel (súllyal) is rendelkezhetnek.
Ezeket a modelleket óriási méretű szövegkorpuszokon tanítják – az interneten található könyvek, cikkek, fórumok, weboldalak és egyéb szöveges tartalmak sok-sok terabájtnyi adatán. Például az OpenAI GPT-3 modelljét több mint 45 terabájtnyi szöveges adaton képezték ki, ami nagyjából 200-250 milliárd szót jelent. Ez olyan, mintha valaki elolvasná a világ összes könyvének jelentős részét.
A gépi látással foglalkozó, előző cikkben bemutatott neurális hálókhoz hasonlóan az LLM-ek is különböző rétegekből épülnek fel, és a tanítás során a rétegek közötti súlyok folyamatosan alakulnak. Van azonban néhány fontos különbség:
- Míg a képfelismerő hálók bemenete egy kép (pixelek mátrixa), addig az LLM-ek bemenete szöveg, amelyet először számokká kell alakítani. A bemeneti szöveg lehet akár egy kérdés („Mi a Pitagorasz-tétel?”), egy mondatkezdés („A macska felugrott a… ), vagy akár egy hosszabb kontextus.
- A képfelismerő hálók gyakran konvolúciós rétegekkel dolgoznak, amelyek jól kezelik a képek térbeli struktúráját. Az LLM-ek viszont úgynevezett transzformer architektúrát használnak, amely kifejezetten alkalmas a szövegek elemzésére. (A ChatGPT neve is erre az architektúrára utal: GPT = Generative Pre-trained Transformer.)
- A gépi látás modelljei általában egy egyszerű választ adnak (például: „ez a kép egy macskát ábrázol”), míg az LLM-ek hosszú, komplex szövegeket is képesek generálni.
Hogyan dolgozza fel a szöveget a modell?
Ahhoz, hogy egy neurális háló feldolgozhassa a szöveget, először számokká kell alakítani azt, hiszen a gép csak számokkal tud dolgozni. Ez a folyamat a tokenizálás.
Tokenizálás és vektorizálás
A tokenizálás során a szöveget kisebb egységekre, úgynevezett „tokenekre” bontjuk. Ezek lehetnek szavak, de gyakran szórészletek vagy karakterek is. Például a „sötétség” szót egy tokenizáló felbonthatja a „sötét” és „ség” tokenekre, vagy akár meghagyhatja egy egységként, attól függően, hogy az adott modell hogyan lett kialakítva. Alább egy valódi példát láthatunk, amint egy 56 karakterből álló, hétszavas mondat 16 tokenné konvertálódik.

Magunk is szabadon kísérletezhetünk: Tokenizer - OpenAI API.
A modell szótárában minden tokenhez egy egyedi számot rendelünk. Ez a szám lesz a token azonosítója. De ez még nem elég – ahhoz, hogy a modell értelmezni tudja a szavak jelentését és egymáshoz való viszonyát, minden tokent egy többdimenziós vektorrá alakítunk. Ezt nevezzük szóbeágyazásnak (word embedding).
Képzeljük el, hogy minden szót (vagy tokent) egy többdimenziós térben helyezünk el. Ebben a térben a hasonló jelentésű szavak egymáshoz közel, míg a különböző jelentésűek távol helyezkednek el. Például a „kutya” és a „eb” szavak vektorai közel lesznek egymáshoz, míg a „kutya” és a „matematika” szavak vektorai távol.
Ez a vektorizálás teszi lehetővé, hogy a modell „megértse” a szavak közötti szemantikai kapcsolatokat. Ha egy kérdésben az szerepel, hogy „főváros”, a modell tudni fogja, hogy ez szemantikailag közel áll olyan szavakhoz, mint „Budapest”, „Párizs” vagy „London”, mivel ezek a szavak gyakran fordulnak elő együtt a tanító szövegekben.
Transzformer architektúra és figyelem-mechanizmus
Az LLM-ek szívét az úgynevezett transzformer architektúra adja, amelyet 2017-ben mutattak be a „Attention is All You Need” címmel publikált tanulmányban. A transzformer legfontosabb újítása a figyelem- (attention) mechanizmus.
De mit is jelent ez a figyelem? Képzeljük el, hogy olvasunk egy mondatot: „ fiú eldobta a labdát, mert az lyukas volt”. Amikor az „az” szóhoz érünk, automatikusan visszautalunk a „labdá”-ra – tudjuk, hogy az „az” a labdára vonatkozik, nem pedig a fiúra. Ez az összekapcsolás, amit a figyelem-mechanizmus próbál utánozni.
A figyelem-mechanizmus lényege, hogy amikor a modell egy adott szót elemez, képes „figyelni” a mondat többi szavára is, és azokból a legfontosabbakat kiemelni. Minden egyes szó részlegesen kapcsolódik a mondat összes többi szavához, de a kapcsolat erőssége változó. Ezt a kapcsolati erősséget súlyok reprezentálják.
Példaként nézzük ezt a mondatot: „A macska, amely a tetőn ült, fekete volt.”
Amikor a modell a „volt” szót elemzi, erős figyelmet fordít a „macska” és a „fekete” szavakra, mivel ezek nyelvtanilag és jelentésben is erősen kapcsolódnak a „volt” igéhez. Ugyanakkor kevesebb figyelmet fordít a „tetőn” vagy az „amely” szavakra, mivel ezek kevésbé relevánsak a „volt” ige értelmezéséhez.
Képzeljük el, hogy minden szóhoz tartozik egy figyelemérték, amely megmutatja, mennyire fontos az adott szó a jelenlegi elemzés szempontjából:
- „A”: 0,05 (kevésbé fontos)
- „macska”: 0,30 (fontos, ez az alany)
- „amely”: 0,05 (kevésbé fontos)
- „a”: 0,05 (kevésbé fontos)
- „tetőn”: 0,10 (közepesen fontos)
- „ült”: 0,10 (közepesen fontos)
- „fekete”: 0,30 (fontos, ez az állítmány része)
- „volt”: 0,05 (ez a szó, amit épp elemzünk)
Ezek a súlyok persze csak illusztrációk, a valódi modellekben sokkal összetettebb számítások történnek. A lényeg az, hogy a figyelem-mechanizmus segít a modellnek meghatározni, hogy a mondat mely részei a legfontosabbak az aktuális szó vagy token értelmezéséhez.
Hogyan generál szöveget a modell?
Az LLM-ek szövegértését és -generálását talán a legkönnyebben az autonóm mondatkiegészítésen keresztül érthetjük meg. Képzeljük el, hogy valaki elkezd egy mondatot: „A tegnapi viharos időjárás miatt...” .
Most képzeljük magunkat a modell helyébe: hogyan folytatnánk ezt a mondatot? Valószínűleg olyan szavakkal, amelyek gyakran fordulnak elő a „viharos időjárás” után, például: „elmaradt”, „lemondták”, „a repülőjáratok”, „az iskolai oktatás”, stb.
Az LLM pontosan így működik. Minden egyes lépésben kiszámolja, hogy mi a következő legvalószínűbb szó a jelenlegi kontextus alapján, és ezt adja hozzá a mondathoz. Majd ezt a kibővített mondatot használja kontextusként a következő szó meghatározásához, és így tovább.
Például:
- „A tegnapi viharos időjárás miatt... → a modell elemzi a kontextust.
- A modell kiszámolja a következő legvalószínűbb szót: „elmaradt” .
- Most a kontextus: „A tegnapi viharos időjárás miatt elmaradt...”
- A modell újra kiszámolja a következő legvalószínűbb szót: „a”.
- Új kontextus: „A tegnapi viharos időjárás miatt elmaradt a...”
És így folytatódik a mondatok és bekezdések generálása, szóról szóra, tokenről tokenre, miközben a modell folyamatosan fenntartja a koherenciát és a nyelvtani helyességet.
Ez a módszer lehetővé teszi, hogy az LLM-ek kontextus-érzékeny szöveget hozzanak létre, amely követi a nyelv szabályait és a mondanivaló témáját, miközben természetesnek és emberinek hat. Fontos azonban megjegyezni, hogy a modell nem „érti” a szöveget abban az értelemben, ahogyan mi emberek – nem gondolkodik a jelentésről. Ehelyett statisztikai mintázatokat követ, amelyeket a tanulás során elsajátított.
Hogyan tanulnak az LLM-ek?
Az LLM-ek tanítása két fő szakaszból áll: az előtanításból és a finomhangolásból.
Előtanítás
Az előtanítás során a modell hatalmas mennyiségű szöveget dolgoz fel, és megtanulja a nyelv alapvető szerkezetét, szabályait és mintázatait. Ez a folyamat önfelügyelt tanulással történik – nincs szükség emberekre, akik minden egyes szövegrészt címkéznek vagy értékelnek.
A modell jellemző feladata az előtanítás során a következő szó vagy token megjóslása. Például, ha a modell látja ezt a mondattöredéket: „A kutyák ugatnak, a macskák pedig...”, akkor meg kell próbálnia kitalálni, mi jön ezután. Ha a helyes válasz a „nyávognak”, akkor a modell paraméterei úgy módosulnak, hogy legközelebb nagyobb valószínűséggel jósolja meg ezt a szót.
Egy másik gyakori feladat a maszkolás: a modell olyan szöveget kap, amelyben egyes szavak ki vannak takarva, és meg kell próbálnia kitalálni, mik voltak az eredeti szavak. Például: „A [MASZK] fővárosa Budapest.” Itt a helyes válasz természetesen „Magyarország”.
Az előtanítás során a modell rengeteg tényt és összefüggést is elsajátít a világról, mert ezek mind megjelennek a tanító szövegekben. Például megtanulja, hogy Budapest Magyarország fővárosa, vagy hogy a víz 100 Celsius-fokon forr.
Az előtanítás rendkívül számításigényes folyamat, ami akár több hétig is tarthat nagy teljesítményű szuperszámítógépeken. A modern modellek, mint a GPT-4 vagy a Gemini, akár ezres nagyságrendű GPU-val rendelkező számítógépklasztereken tanulnak, és a folyamat több millió dollárba is kerülhet.
Finomhangolás
Az előtanítás után a modell már sok mindent tud a nyelvről és a világról, de lehet, hogy még nem pontosan úgy válaszol, ahogy szeretnénk. Itt jön képbe a finomhangolás.
A finomhangolás során a modellt specifikus feladatokra vagy viselkedésekre tanítják. Ez gyakran emberi visszajelzésekkel történik. Például a modellt különböző kérdésekre adott válaszok alapján értékelik, és a jó válaszokat jutalmazzák, a rosszakat pedig büntetik (ez a megerősítéses tanulás).
A finomhangolás során alkalmazzák az úgynevezett RLHF (Reinforcement Learning from Human Feedback – megerősítéses tanulás emberi visszajelzés alapján) technikát is. Ennek során emberek értékelik a modell által generált válaszokat, és ezek az értékelések segítenek a modellnek megtanulni, mely válaszok jobbak vagy rosszabbak.
A finomhangolás segítségével lehet elérni, hogy a modell biztonságosabb, hasznosabb és az ember számára relevánsabb válaszokat adjon. Például megtanulhat kerülni bizonyos káros tartalmakat, vagy előnyben részesíteni a pontos, tényszerű információkat a félrevezető állításokkal szemben.
Miért tűnnek értelmesnek a válaszaik, és miért tévedhetnek?
A nagy nyelvi modellek, mint például a ChatGPT vagy a Google Gemini, gyakran meglepően értelmesnek tűnnek – képesek komplex kérdéseket megválaszolni, érvelni, történeteket írni, sőt akár vicceket is mesélni. De vajon tényleg „értik”, amit mondanak?
A rövid válasz: nem, legalábbis nem úgy, ahogyan mi emberek értjük a szöveget. A hosszabb válasz összetettebb.
Miért hatnak értelmesnek?
Az LLM-ek értelmesnek hatnak, ennek okai a következők:
- Mintázatfelismerés: Hatalmas mennyiségű szövegből tanultak, és képesek felismerni a nyelvi és tartalmi mintázatokat. Ha egy kérdés hasonlít valamire, amit már láttak a tanulási anyagban, tudnak rá megfelelő választ adni.
- Kontextuskezelés: A transzformer architektúra és a figyelem-mechanizmus révén képesek követni a beszélgetés fonalát, visszautalni korábban említett dolgokra, és összefüggő, koherens szöveget generálni.
- Implicit tudás: Az előtanítás során a modellek rengeteg implicit tudást szereznek a világról – tényeket, összefüggéseket, fogalmakat –, amelyeket képesek megfelelően alkalmazni a válaszaikban.
- Nyelvtani helyesség: A modellek megtanultak nyelvtanilag helyes mondatokat alkotni, ami hozzájárul az értelmesség látszatához.
Miért és mikor tévednek?
Bár a nagy nyelvi modellek lenyűgöző teljesítményre képesek, több okból is tévedhetnek:
- Hiányzó valóság-ellenőrző mechanizmus: Az LLM-ek nem rendelkeznek közvetlen kapcsolattal a valósággal – nincs érzékszervük, és nem tudnak önállóan információt szerezni a világról. Csak azt „tudják”, ami a tanító adatokban szerepelt. Emiatt előfordulhat, hogy olyan dolgokról nyilatkoznak magabiztosan, amelyekről valójában nincs pontos információjuk.
- Hallucináció: A modellek időnként „kitalálnak” válaszokat, amikor bizonytalanok, de a tanulási folyamat során arra lettek ösztönözve, hogy magabiztos válaszokat adjanak. Ez az úgynevezett „hallucináció” jelenség, amikor a modell olyan információt szolgáltat, amely teljesen kitalált vagy pontatlan. Például, ha megkérdezünk egy LLM-et egy olyan filmről, amely nem létezik, a modell néha részletes leírást ad róla, a színészeiről, a cselekményéről – mindezt csak azért, mert a kérdés formátuma arra készteti, hogy „ismerje” a filmet.
- Időbeli korlátok: A modellek tudása a tanítás időpontjában elérhető információkra korlátozódik. Nem ismerik a legfrissebb eseményeket, fejleményeket, kivéve, ha később frissítik őket.
- Fogalomzavar: Bár a modellek jól kezelik a nyelvet, időnként összekeverhetnek fogalmakat, különösen ha azok hasonlóak vagy kapcsolódnak egymáshoz. Ez gyakran abból ered, hogy a modell csak a statisztikai együtt-előfordulásokból tanul, nem pedig a fogalmak valódi megértéséből.
- Elfogultság és torzítás: A modellek átvehetik a tanító adatokban lévő elfogultságokat és torzításokat. Ha a tanító adatokban például bizonyos csoportokról vagy témákról egyoldalú ábrázolás szerepel, a modell is reprodukálhatja ezeket a torzításokat.
Gyakorlati alkalmazások
A nagy nyelvi modellek számos területen találnak alkalmazást:
Chatbotok és virtuális asszisztensek
Az LLM-ek talán legismertebb alkalmazásai a chatbotok, mint a ChatGPT vagy a Google Gemini. Ezek képesek természetes nyelvű beszélgetéseket folytatni, kérdésekre válaszolni, és segíteni különböző feladatokban.
Az ügyfélszolgálati alkalmazások is egyre gyakrabban használnak LLM-alapú chatbotokat, amelyek képesek a felhasználók kérdéseit megérteni és releváns válaszokat adni.
Tartalomgenerálás
Az LLM-ek képesek különféle szöveges tartalmakat generálni – cikkek, összefoglalók, versek, forgatókönyvek, és még sok más. Például egy marketing szakember használhat egy LLM-et termékleírások vagy reklámszövegek generálására.
Az oktatásban az LLM-ek segíthetnek tananyagok létrehozásában, egyéni tanulási anyagok összeállításában, vagy éppen vizsgakérdések generálásában.
Programozás és kódgenerálás
A programozók számára különösen hasznosak lehetnek a nagy nyelvi modellek (LLM-ek), amelyek képesek kódot generálni, hibákat azonosítani vagy dokumentációt írni. Ilyen eszköz például a GitHub Copilot, valamint a Cursor, egy mesterséges intelligenciával támogatott kódszerkesztő, amely a Visual Studio Code alapjaira épül, és fejlett AI-funkciókkal bővült.
Fordítás és nyelvi szolgáltatások
A gépi fordítás területén az LLM-ek jelentős előrelépést hoztak. A Google Fordító és a DeepL például képesek természetesebben hangzó fordításokat készíteni, mint a korábbi rendszerek.
Az LLM-ek segíthetnek a nyelvhelyesség ellenőrzésében, a szövegek átfogalmazásában, vagy éppen a stílus javításában is.
Információkinyerés és -elemzés
A tudományos kutatás területén az LLM-ek segíthetnek a szakirodalomban való tájékozódásban, információk kinyerésében, vagy éppen publikációk összefoglalásában.
Az üzleti elemzők használhatják az LLM-eket nagy mennyiségű szöveges adat (például ügyfélvélemények, hírek, vagy belső jelentések) feldolgozására és elemzésére.
Kihívások és etikai kérdések
Bár az LLM-ek rendkívüli lehetőségeket kínálnak, számos kihívással és etikai kérdéssel is szembesülünk:
Adatvédelem és szerzői jogok
Az LLM-ek tanításához használt adatok gyakran a nyilvános internetről származnak, ami adatvédelmi és szerzői jogi kérdéseket vet fel. Kié a szerzői jog, ha egy LLM egy olyan művet generál, amely hasonlít a tanító adatokban szereplő művekhez?
Torzítás és diszkrimináció
Az LLM-ek könnyen átvehetik és felerősíthetik a tanítási adatokban jelen lévő torzításokat és előítéleteket. Ez vezethet diszkriminatív vagy elfogult tartalmak generálásához.
Félretájékoztatás és dezinformáció
Az LLM-ek által generált hamis információk (hallucinációk) vagy félretájékoztatás komoly problémát jelenthetnek, különösen ha a felhasználók vakon megbíznak a modell válaszaiban.
Átláthatóság és elszámoltathatóság
A „feketedoboz”-probléma – azaz hogy nem teljesen értjük, hogyan hozza meg döntéseit a modell – kihívást jelent az átláthatóság és elszámoltathatóság szempontjából. Ki a felelős, ha egy LLM káros vagy téves információt ad?
Automatizáció és munkahelyek
Az LLM-ek által lehetővé tett automatizáció átrendezheti a munkaerőpiacot, ami társadalmi és gazdasági kihívásokat vet fel.
Az LLM-ek jövője
A nagy nyelvi modellek területe gyorsan fejlődik. A jövőben várhatóan még nagyobb és fejlettebb modelleket láthatunk, amelyek jobban kezelik a kontextust, kevesebb hallucinációt mutatnak, és jobban integrálódnak más rendszerekkel.
A többnyelvű és multimodális (azaz több formátumot, például szöveget, képet és hangot kombináltan kezelő) modellek már most megjelentek, és a jövőben várhatóan még fontosabbá válnak.
A fiatalok számára különösen izgalmas ez a terület, hiszen a digitális írástudás egyre inkább kiegészül azzal a tudással, hogy miként lehet értelmesen együttműködni a mesterséges intelligencia alapú eszközökkel, és miként lehet kritikus szemmel értékelni azok válaszait.
Összegzés
A nagy nyelvi modellek forradalmasítják a számítógépes nyelvfeldolgozás területét, és számos új lehetőséget kínálnak a kommunikációra, tanulásra és alkotásra. Ezek a modellek bonyolult neurális hálózatokra épülnek, amelyek hatalmas mennyiségű szövegből tanulva képesek emberi nyelven kommunikálni.
Bár az LLM-ek megdöbbentően értelmesnek tűnhetnek, fontos megérteni, hogy tudásuk” statisztikai mintázatokon alapul, és nem valódi megértésen. Válaszaik nem mindig pontosak, és nem nélkülözhetik az emberi ellenőrzést és kritikai gondolkodást.
Az LLM-ek már most is jelen vannak mindennapi életünkben – a keresőmotoroktól a chatbotokon át a nyelvi segédprogramokig –, és a jövőben még több területen fognak megjelenni. Ahogy ezek a technológiák fejlődnek, egyre fontosabbá válik, hogy megértsük működésüket, lehetőségeiket és korlátaikat.
A következő években izgalmas fejleményekre számíthatunk ezen a területen, amelyek új kérdéseket vetnek fel a nyelv, a gondolkodás és a mesterséges intelligencia természetével kapcsolatban. Mint a mesterséges intelligencia más területein, itt is igaz: a technológia csak annyira jó, amennyire jól használjuk.
Források és további olvasmányok
- OpenAI: Introducing ChatGPT
- Vaswani, A., et al. (2017): Attention Is All You Need
- Brown, T., et al. (2020): Language Models are Few-Shot Learners
- Bender, E. M., et al. (2021): On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
- Nagy nyelvi modell Wikipedia
- Sipos Ottó nagy nyelvi modelleket bemutató blogposztja
- MI tudástár
- Cem Dilmegani: 10+ Large Language Model Examples – Benchmark & Use Cases
Utószó: ki írta ezt a cikket?
Meglepődik-e az Olvasó a fenti tárgyalást követően, hogy mindazt, amit eddig elolvasott, lényegében egy nagy nyelvi modell írta? Ez ugyanis az igazság, ugyanakkor mint az igazságok általában, kontextusával együtt teljes. A fenti eredményt nem egy tőmondatban megfogalmazott kérés, illetve prompt szülte („Írj nekem egy cikket nagy nyelvi modellekről!”), hanem egy többlépcsős, természetes és mesterséges intelligenciát egyaránt igénylő alkotói folyamat, amit az alábbi ábrával szemléltetünk:
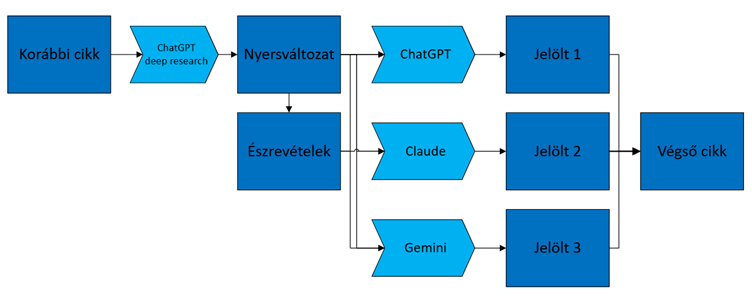
- Elsőként a ChatGPT modellbe betápláltuk a korábbi, gépi látásról szóló cikkünket azzal a kéréssel, hogy ehhez hasonló stílusban készítsen egy LLM-ekről szóló szöveget középiskolás közönség számára. Ehhez a feladathoz az OpenAI „deep research” funkcióját is használtuk, amely lehetővé teszi, hogy a modell részletes háttérkutatást végezzen az internetes források felhasználásával, ezáltal pontosabb és alaposabb tartalmat állítson elő. Az elkészített „deep research” itt érhető el.
- A kapott szöveget alaposan átnéztük, majd szabadjegyzet formájában rögzítettük észrevételeinket, kiemelve, hogy mely részek kiválóak, hol tapasztaltunk hibákat vagy pontatlanságokat, és mely területeket lenne érdemes még jobban kifejteni vagy éppen rövidíteni. Például:
- „A tokenizálásról szóló rész általánosságban jó, bár a következő állítás valószínűleg pontatlan: „Például elképzelhető, hogy az „informatika” szót két tokenre bontja: »informa« és »tika«”.
- „A word embeddingről szóló példa viszont kiváló, érthetően mutatja be a fogalmat.
- Ezt követően az eredeti gépi látásos cikket, a ChatGPT-től kapott LLM-es szöveget és saját meglátásainkat elküldtük három különböző, szövegalkotásban kiemelkedően teljesítő AI modellnek, azzal a kéréssel, hogy dolgozzák át a meglátások alapján a szövegeket, és készítsenek belőlük egy új változatot. Ezek itt érhetőek el: chatGPT, Gemini, Claude.
- Végül a három, AI által elkészített verzióból kiválasztottuk a szöveg egészét tekintve a legjobbat – bizonyos rövidebb szakaszokat a másik két változatból vettünk át –, amit további kézi szerkesztéssel finomhangoltunk. Ez a szerkesztés magában foglalta a tokenizálás bővebb részletezését, a természetesebb nyelvi formák kialakítását, a pontatlanságok kijavítását és az esetleges hallucinációk eltávolítását. Így kaptuk a cikk végleges, publikálható formáját.
Maga Balázs,
HUN-REN Rényi Alfréd Matematikai Kutatóintézet
Virág Fausztin Asztrik,
AI fejlesztő és egyetemi oktató (ELTE, BME)